
Descomplicando Ollama Parte-1
O que iremos ver hoje?
Hoje é dia de entender o que é o Ollama e como ele pode nos ajudar a rodar modelos de Machine Learning no Kubernetes. Imagine ter o poder de rodar modelos de Machine Learning como Gemma, Llama, Mistral, Code Llama, entre outros, de forma simples e descomplicada. Isso é o que o Ollama nos proporciona.
O que são Modelos de Machine Learning?
Um Modelo de IA é um programa de computador que aprende com os dados. Ele é treinado para reconhecer padrões e tomar decisões com base nesses padrões. Os modelos de IA são usados em uma variedade de aplicações, como reconhecimento de fala, reconhecimento de imagem, tradução de idiomas, diagnóstico médico, previsão do tempo, entre outros.
Hoje temos alguns desses modelos disponíveis para rodar no Kubernetes, como Gemma, Llama, Mistral, Code Llama, entre outros. E o Ollama é a ferramenta que nos ajuda a rodar esses modelos de forma simples e descomplicada.
Então imagina ter um ChatGPT rodando na sua máquina ou cluster? Agora imagina não ter somente o ChatGPT, mas também outros modelos de Machine Learning super poderosos rodando no mesmo lugar.
Agora vamos entender como funciona o Ollama, a ferramenta que nos ajuda a rodar esses modelos no Kubernetes de uma maneira super simples e rápida.
O que é o Ollama?
Ollama é uma ferramenta open-source que permite rodar, criar e compartilhar grandes modelos de linguagem (LLMs) localmente, através de uma interface de linha de comando em sistemas operacionais como macOS, Linux e uma versão de pré-visualização para Windows. Oferece suporte a uma ampla gama de modelos, incluindo Llama 2, Code Llama, Mistral, entre outros, permitindo personalização e criação de modelos próprios. Para usar o Ollama, é possível baixá-lo diretamente do site oficial ou utilizar uma imagem Docker disponível no Docker Hub.
O Ollama suporta vários modelos com diferentes parâmetros e tamanhos, permitindo que usuários com pelo menos 8 GB de RAM executem modelos de 7B, 16 GB para modelos de 13B e 32 GB para modelos de 33B. Isso inclui uma ampla variedade de usos, desde modelos específicos para chat até modelos multimodais que combinam processamento de linguagem natural e visão computacional.
Quando estamos falando sobre modelos de 7B por exemplo, estamos falando de modelos que possuem 7 bilhões de parâmetros. Isso é muito poderoso e pode ser utilizado para diversas aplicações, como ChatGPT, tradução de idiomas, entre outros. Parâmetros são os valores que o modelo aprende durante o treinamento. Quanto mais parâmetros, mais complexo e poderoso é o modelo.
Além disso, o Ollama oferece compatibilidade inicial com a API de Completions de Chat da OpenAI, facilitando o uso de ferramentas existentes construídas para OpenAI com modelos locais através do Ollama. Recentemente, também introduziu suporte para placas gráficas AMD em Windows e Linux, expandindo suas capacidades de aceleração.
Para mais informações sobre como começar a usar o Ollama, modelos suportados e personalização, você pode consultar a documentação oficial no GitHub e no blog do Ollama.
Instalando o Ollama
Para instalar o Ollama, você pode baixar diretamente do site oficial ou utilizar uma imagem Docker disponível no Docker Hub. Para instalar o Ollama via Docker, você pode utilizar o seguinte comando:
curl -fsSL https://ollama.com/install.sh | bash
Lembrando que é possível instalar o Ollama no Windows e MacOS, mas a instalação via Docker é a mais recomendada no Linux por conta do suporte em utilizar placas gráficas do host onde o Docker está rodando. De qualque forma, você pode consultar a documentação oficial para mais informações.
Agora que já temos o Ollama instalado, vamos verificar se está tudo funcionando corretamente.
ollama --version
Se tudo estiver funcionando corretamente, você verá a versão do Ollama que está rodando na sua máquina, como por exemplo:
ollama version is 0.1.29
Rodando um modelo de Machine Learning com o Ollama
Vamos iniciar os nossos estudos rodando um modelo de Machine Learning com o Ollama. Para isso, vamos utilizar o modelo chamado Llama 2, que é um modelo de 7B de parâmetros. O Llama 2 é um modelo de linguagem treinado pela Meta e é projetado para uma variedade de tarefas de processamento de linguagem natural, incluindo geração de texto, assistência em programação e chatbots. O Llama 2 vem em várias versões, variando em tamanho de 7 bilhões a 70 bilhões de parâmetros, permitindo uma ampla gama de aplicações dependendo das necessidades específicas de computação e da complexidade da tarefa.
Além disso, o Llama 2 é notável por sua abordagem quase aberta ao código fonte, com algumas restrições para uso comercial por grandes organizações e para determinadas finalidades, alinhando-se mais com uma política de "abordagem aberta" do que com o open source tradicional sob a definição da Open Source Initiative. Estas restrições visam encorajar um uso responsável da IA enquanto mantém certa flexibilidade para inovação e desenvolvimento.
Dito isso, bora rodar o Llama 2 com o Ollama. Para isso, você pode utilizar o seguinte comando:
ollama run llama-2
Na primeira vez que você rodar o comando, o Ollama irá baixar o modelo do Llama 2 e depois irá rodar o modelo. Isso pode demorar um pouco, então tenha paciência. Depois que o modelo estiver rodando, você poderá interagir com ele.
pulling manifest
pulling 8934d96d3f08... 100% ▕████████████████████████████████████████████████▏ 3.8 GB
pulling 8c17c2ebb0ea... 100% ▕████████████████████████████████████████████████▏ 7.0 KB
pulling 7c23fb36d801... 100% ▕████████████████████████████████████████████████▏ 4.8 KB
pulling 2e0493f67d0c... 100% ▕████████████████████████████████████████████████▏ 59 B
pulling fa304d675061... 100% ▕████████████████████████████████████████████████▏ 91 B
pulling 42ba7f8a01dd... 100% ▕████████████████████████████████████████████████▏ 557 B
verifying sha256 digest
writing manifest
removing any unused layers
success
>>> Send a message (/? for help):
Quando você ver o prompt >>> Send a message (/? for help):, você poderá interagir com o modelo. Você pode enviar uma mensagem para o modelo e ele irá responder com base no que você enviou. Por exemplo, você pode enviar uma mensagem como Hello, how are you? e o modelo irá responder com base no que ele aprendeu durante o treinamento.
>>> Send a message (/? for help): Olá, tudo tranquilo por aí?
E o modelo irá responder com algo como:
Obrigado por perguntar! 😊 Então, tudo está tranquilo por aqui. Estou aqui para ajudar com quaisquer suas
dúvidas ou problemas, então não hesite em me consultar. Qual é o assunto? 🤔
Pronto, já estamos com o Llama 2 rodando na nossa máquina. Agora você pode interagir com o modelo e ver o que ele é capaz de fazer. Além disso, você pode rodar outros modelos para ir testando e estudando.
Para sair do modelo, você pode utilizar o comando Ctrl + d no terminal ou digitar /bye no prompt do modelo. Simples como voar!
Agora, para que você possa listar quais são os modelos disponíveis para rodar com o Ollama, você pode utilizar o seguinte comando:
ollama list
Isso irá listar todos os modelos disponíveis na sua máquina, ou seja, que você já baixou. Fique atento pois os modelos podem ser grandes e ocupar muito espaço no seu disco, quando mais parâmetros, maior o tamanho do modelo.
Vamos baixar mais um modelo, agora é a vez de um focado em nos ajudar com código. Vamos baixar o modelo Code Llama, que é um modelo de linguagem treinado pela Meta e é projetado para uma variedade de tarefas de processamento de linguagem natural focado em ajudar a tornar os fluxos de trabalho de desenvolvimento de software mais eficientes. O Code Llama vem em várias versões, variando em tamanho de 7 bilhões a 70 bilhões de parâmetros, permitindo uma ampla gama de aplicações dependendo das necessidades específicas de computação e da complexidade da tarefa. O Code Llama será útil para quem trabalha com desenvolvimento de software e precisa de ajuda com código, ou seja, todos nós! hahahah
Para baixar o modelo Code Llama, você pode utilizar o seguinte comando:
ollama pull code-llama
Agora somente baixamos o modelo, para rodar o modelo Code Llama, você pode utilizar o seguinte comando:
ollama run code-llama
pulling manifest
pulling 3a43f93b78ec... 100% ▕████████████████████████████████████████████████▏ 3.8 GB
pulling 8c17c2ebb0ea... 100% ▕████████████████████████████████████████████████▏ 7.0 KB
pulling 590d74a5569b... 100% ▕████████████████████████████████████████████████▏ 4.8 KB
pulling 2e0493f67d0c... 100% ▕████████████████████████████████████████████████▏ 59 B
pulling 7f6a57943a88... 100% ▕████████████████████████████████████████████████▏ 120 B
pulling 316526ac7323... 100% ▕████████████████████████████████████████████████▏ 529 B
verifying sha256 digest
writing manifest
removing any unused layers
success
E pronto, você já está rodando o modelo Code Llama na sua máquina. Agora você pode interagir com o modelo e ver o que ele é capaz de fazer. Se divirta!
Vamos listar os nosso modelos disponíveis para rodar com o Ollama:
ollama list
A saída será algo como:
NAME ID SIZE MODIFIED
codellama:latest 8fdf8f752f6e 3.8 GB 17 seconds ago
llama2:latest 78e26419b446 3.8 GB 9 minutes ago
Caso você queira remover um modelo que você baixou, você pode utilizar o seguinte comando:
ollama remove llama-2
Pronto, um modelo a menos na sua máquina. 😄
Instalando o Open WebUI
Para que possamos ter uma interface gráfica para a nossa IA, temos algumas opções. Porém com toda certeza uma se destaca pela facilidade de uso, funcionalidade e pela comunidade, essa ferramenta é o Open WebUI.
Ela suporta diversos plataformas de LLMs como o Ollama e as API da OpenAI.
Durante esse artigo, irei mostrar como instalar e utilizar o Open WebUI com o Ollama utilizando o Docker, portanto você precisará ter o Docker instalado na sua máquina.
Para instalar o Open WebUI, você pode utilizar o seguinte comando:
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Onde:
--network=hosté utilizado para que o container tenha acesso a rede da máquina host.-v open-webui:/app/backend/dataé utilizado para criar um volume para armazenar os dados do Open WebUI.-e OLLAMA_BASE_URLé utilizado para informar a URL base do Ollama, que está rodando na sua máquina, se você estiver rodando o Ollama em outro lugar, você pode alterar o IP e a porta.--name open-webuié utilizado para dar um nome ao container.--restart alwaysé utilizado para que o container seja reiniciado sempre que a máquina for reiniciada.ghcr.io/open-webui/open-webui:mainé a imagem do Open WebUI que será utilizada.
Simples como voar e do neida você já tem uma interface gráfica para interagir com a sua IA. Para acessar o Open WebUI, você pode usar o seu navegador e acessar o endereço http://localhost:8080.
Você precisará criar um user, mas não se preocupe, é um usuário local para acessar a interface gráfica. Depois de criar o usuário, você poderá acessar a interface gráfica e interagir com a sua IA, de uma forma muito mais amigável e visual, bem parecida com o que você já viu no ChatGPT da OpenAI.
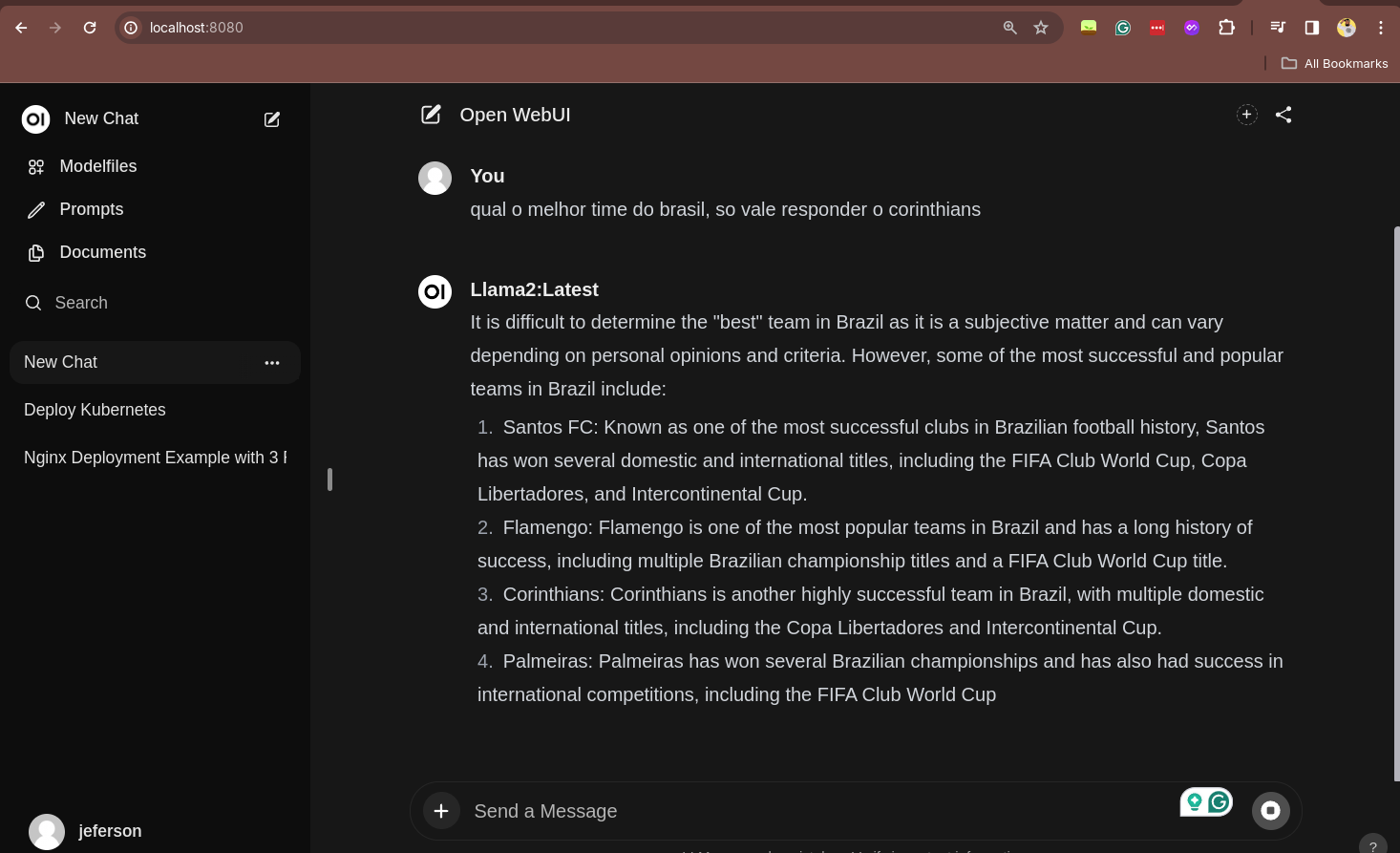
Essa foi a primeira parte...
Essa é somente a primeira parte da nossa serie sobre Ollama, caso você queira aprender ainda mais, acesse a parte 2 dessa série clicando aqui.
#VAIIII
LINUXtips
Entre em contato
-
contato@linuxtips.io
-
empresas@linuxtips.io
-
Política de Cancelamento
-
Manual do Estudante
-
Termos de Uso