
Descomplicando Ollama Parte-2
Instalando o Ollama no Kubernetes
Agora que já sabemos como o Ollama funciona, bora entender como fazer com que ele funcione no Kubernetes de uma maneira simples e descomplicada, como é a nossa proposta aqui no Descomplicando.
Eu estou utilizando o Minikube para esse exemplo, caso você queira saber como eu instalei e o quais os comandos que eu utilizei, vou colar aqui para você:
minikube start --driver docker --container-runtime docker --gpus all
Onde:
--driver dockeré utilizado para que o Minikube utilize o Docker como driver.--container-runtime dockeré utilizado para que o Minikube utilize o Docker como container runtime.--gpus allé utilizado para que o Minikube utilize todas as GPUs disponíveis no host.
Super simples! Lembre-se sempre de ativar as GPUs no Minikube para que você possa utilizar as GPUs no Kubernetes.
Ahhh, eu também já adicionei o Ingress Controller, no caso o Nginx Ingress Controller. Para instala-lo no Minikube é super simples:
minikube addons enable ingress
Agora sim! Já temos o Minikube rodando com o Docker como driver, com todas as GPUs disponíveis e com o Ingress Controller habilitado. \o/
Uma coisa que me deixa super feliz é a existência do Helm, que é um gerenciador de pacotes para Kubernetes. Com o Helm, podemos instalar aplicações no Kubernetes de uma maneira super simples! E o melhor, o Ollama já possui um chart Helm disponível para que possamos instalar o Ollama no Kubernetes.
Conheça todos os detalhes e opções disponíveis no chart Helm do Ollama.
Para o nosso exemplo, vamos utilizar o chart Helm do Ollama para instalar o Ollama no Kubernetes. Para isso, você precisa ter o Helm instalado na sua máquina. Se você ainda não tem o Helm instalado, você pode seguir o guia de instalação do Helm.
Agora com o Helm instalado, vamos adicionar o repositório do Ollama no Helm para que possamos instalar o Ollama no Kubernetes.
Antes de mais nada, precisamos criar um namespace para o Ollama:
kubectl create namespace ollama
Para adicionar o repositório do Ollama, você pode utilizar o seguinte comando:
helm repo add ollama-helm https://otwld.github.io/ollama-helm/
helm repo update
Com isso já temos o repositório do Ollama adicionado no Helm e atualizado.
Agora precisamos instalar o Ollama, mas antes vamos criar o nosso arquivo values.yaml para configurar o Ollama, mas aqui é somente uma base para você começar, você pode alterar conforme a sua necessidade. E por isso é importante você consultar a documentação oficial do chart Helm do Ollama para saber todas as opções disponíveis.
ollama:
gpu:
# -- Enable GPU integration
enabled: true
# -- GPU type: 'nvidia' or 'amd'
type: 'nvidia'
# -- Specify the number of GPU to 2
number: 1
# -- List of models to pull at container startup
models:
- llama2
ingress:
enabled: true
hosts:
- host: ollama.badtux.io
paths:
- path: /
pathType: Prefix
No meu caso, eu somente tenho um node com GPU, então eu configurei o Ollama para utilizar a GPU, mas você pode alterar conforme a sua necessidade. Além disso, eu configurei para baixar o modelo Llama 2 na inicialização do container e também configurei o Ingress para acessar o Ollama pelo endereço ollama.badtux.io.
Caso seu cluster Kubernetes não tenha suporte a GPU, você pode desabilitar a GPU no Ollama, basta alterar o valor de enabled para false.
Ou ainda, caso o seu cluster tenha mais de uma GPU, você pode alterar o valor de number para a quantidade de GPU que você deseja utilizar.
Ahhh, eu já tenho o DNS configurado para o endereço ollama.badtux.io, apontando para o IP do meu Ingress Controller, então você precisa alterar o valor de host para o endereço que você deseja utilizar para acessar o Ollama.
Inclusive, caso você esteja executando o Kubernetes em um ambiente local, você pode adicionar o endereço no seu arquivo /etc/hosts para que você possa acessar o Ollama pelo endereço configurado no Ingress.
No caso do Minikube, basta digitar o seguinte comando:
echo "$(minikube ip) ollama.badtux.io" | sudo tee -a /etc/hosts
Assim já pegamos o IP do Minikube, que é utilizado pelo Ingress Controller, e adicionamos no arquivo /etc/hosts para que possamos acessar o Ollama pelo endereço ollama.badtux.io. Simples como voar! 😄
Dito isso, agora vamos instalar o Ollama no Kubernetes com o Helm. Para isso, você pode utilizar o seguinte comando:
helm install ollama ollama-helm/ollama -n ollama -f values.yaml
A saída será algo como:
NAME: ollama
LAST DEPLOYED: Wed Mar 27 20:13:29 2024
NAMESPACE: ollama
STATUS: deployed
REVISION: 1
NOTES:
1. Get the application URL by running these commands:
http://ollama.badtux.io/
Pronto, o Ollama foi instalado no Kubernetes, mas ainda temos que esperar os pods ficarem prontos para acessar o Ollama. Para verificar o status dos pods, você pode utilizar o seguinte comando:
kubectl get pods -n ollama
Dependendo da quantidade e do tamanho dos modelos que você configurou para baixar, pode demorar um pouco para os pods ficarem prontos. Então tenha paciência.
Quando os pods estiverem prontos, você poderá acessar o Ollama pelo endereço que você configurou no Ingress. No meu caso, eu posso acessar o Ollama pelo endereço http://ollama.badtux.io/.
Vamos fazer um curl para verificar se o Ollama está funcionando corretamente:
curl http://ollama.badtux.io/
A saída será algo como:
Ollama is running%
Pronto, o nosso Ollama está pronto!
Agora vamos setar a variável de ambiente OLLAMA_HOST para que o CLI do Ollama possa interagir com o Ollama que está no Kubernetes.
export OLLAMA_HOST=http://ollama.badtux.io/
Agora você já pode usar o CLI do Ollama para interagir com o Ollama que está em execução no Kubernetes.
ollama run llama-2
Simples como voar! Agora o nosso Ollama está rodando no Kubernetes! 😄
Instalando o Open WebUI no Kubernetes
O Open WebUI é uma ferramenta super poderosa que nos ajuda a ter uma interface gráfica para interagir com a nossa IA. E o melhor, o Open WebUI já possui um chart Helm, porém nós vamos optar por instalar o Open WebUI no Kubernetes através dos manifestos YAML disponíveis no repositório do Open WebUI.
Não iremos utilizar o chart Helm do Open WebUI, porquê com o chart teríamos que deployar o Ollama utilizando o mesmo chart, pois não tem como desabilitar o Ollama no chart do Open WebUI. Eu vou criar o nosso Helm Chart no futuro, ou ainda, acabar utilizando o Helm Chart do Open WebUI, mas por enquanto vamos utilizar os manifestos YAML disponíveis no repositório do Open WebUI. Ou quem sabe ainda, abrir um PR para adicionar a opção de desabilitar o Ollama no chart do Open WebUI e/ou habilitar o Open WebUI no chart do Ollama. hahahaha (me desculpe caso já exista essa opção e eu não tenha visto).
Vamos criar o nosso arquivo open-webui.yaml para criar o Namespace para o Open WebUI:
apiVersion: v1
kind: Namespace
metadata:
name: open-webui
Agora vamos criar o nosso arquivo webui-deployment.yaml para criar o Deployment do Open WebUI:
apiVersion: apps/v1
kind: Deployment
metadata:
name: open-webui-deployment
namespace: open-webui
spec:
replicas: 1
selector:
matchLabels:
app: open-webui
template:
metadata:
labels:
app: open-webui
spec:
containers:
- name: open-webui
image: ghcr.io/open-webui/open-webui:main
ports:
- containerPort: 8080
resources:
requests:
cpu: "500m"
memory: "500Mi"
limits:
cpu: "1000m"
memory: "1Gi"
env:
- name: OLLAMA_BASE_URL
value: "http://ollama.badtux.io/"
tty: true
volumeMounts:
- name: webui-volume
mountPath: /app/backend/data
volumes:
- name: webui-volume
persistentVolumeClaim:
claimName: ollama-webui-pvc
Eu somente modifiquei o valor de OLLAMA_BASE_URL para o endereço que eu configurei no Ingress do Ollama, no caso http://ollama.badtux.io/.
Fique a vontade para alterar conforme a sua necessidade, inclusive configurações de recursos, volumes, etc.
Com o Deployment criado, precisamos de um Service e na sequência um Ingress para que possamos acessar o Open WebUI.
Para o Service, vamos criar o arquivo webui-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: open-webui-service
namespace: open-webui
spec:
type: NodePort # Use LoadBalancer if you're on a cloud that supports it
selector:
app: open-webui
ports:
- protocol: TCP
port: 8080
targetPort: 8080
# If using NodePort, you can optionally specify the nodePort:
# nodePort: 30000
E para o Ingress, vamos criar o arquivo webui-ingress.yaml:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: open-webui-ingress
namespace: open-webui
#annotations:
# Use appropriate annotations for your Ingress controller, e.g., for NGINX:
# nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: open-webui.badtux.io
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: open-webui-service
port:
number: 8080
Lembrando que você precisa alterar o valor de host para o endereço que você deseja utilizar para acessar o Open WebUI. E caso você esteja utilizando o Minikube, você pode adicionar o endereço no seu arquivo /etc/hosts para que você possa acessar o Open WebUI pelo endereço configurado no Ingress, como eu já falei um zilhão de vezes. hahahah
Agora, para finalizar, vamos criar o arquivo webui-pvc.yaml para criar o PersistentVolumeClaim para o Open WebUI:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
app: ollama-webui
name: ollama-webui-pvc
namespace: open-webui
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 2Gi
Agora sim hein, todos os arquivos que precisamos para o nosso show funcionar estão prontos! Agora vamos aplicar esses arquivos e torcer para que não tenhamos digitados nada errado. 😄
kubectl apply -f open-webui.yaml
kubectl apply -f webui-deployment.yaml
kubectl apply -f webui-service.yaml
kubectl apply -f webui-ingress.yaml
kubectl apply -f webui-pvc.yaml
Lembrando que esse é exatamente o conteúdo do arquivo disponível no repositório do Open WebUI. Clique aqui para acessar o repositório.
Vamos esperar os pods ficarem prontos para acessar o Open WebUI. Para verificar o status dos pods, você pode utilizar o seguinte comando:
kubectl get pods -n open-webui
Quando tudo estiver ok, já podemos acessar o Open WebUI através do endereço que configuramos no Ingress. No meu caso, eu posso acessar o Open WebUI pelo endereço http://open-webui.badtux.io/.
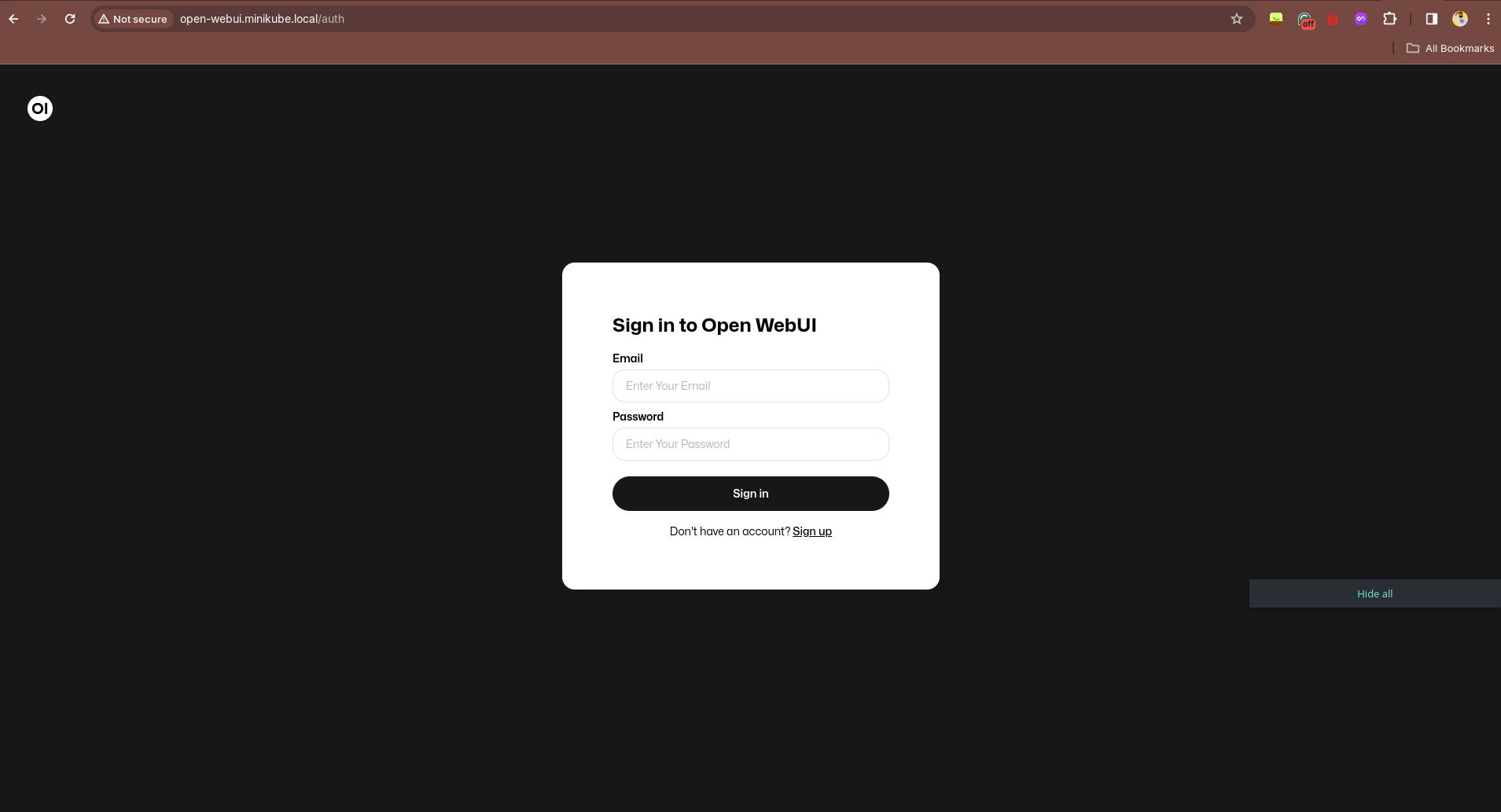
Como ainda não temos um usuário criado, você precisa criar um usuário para acessar o Open WebUI. Depois de criar o usuário, você poderá acessar a interface gráfica e interagir com a sua IA de uma forma muito mais amigável e visual. Os dados são armazenados no PersistentVolumeClaim que criamos, e não é compartilhado com ningúem, então fique tranquilo.
Depois de criado a sua conta, você poderá acessar o Open WebUI e enviar mensagens para a sua IA, ela irá responder com base no que ela aprendeu durante o treinamento e de acordo com o modelo que você está utilizando.
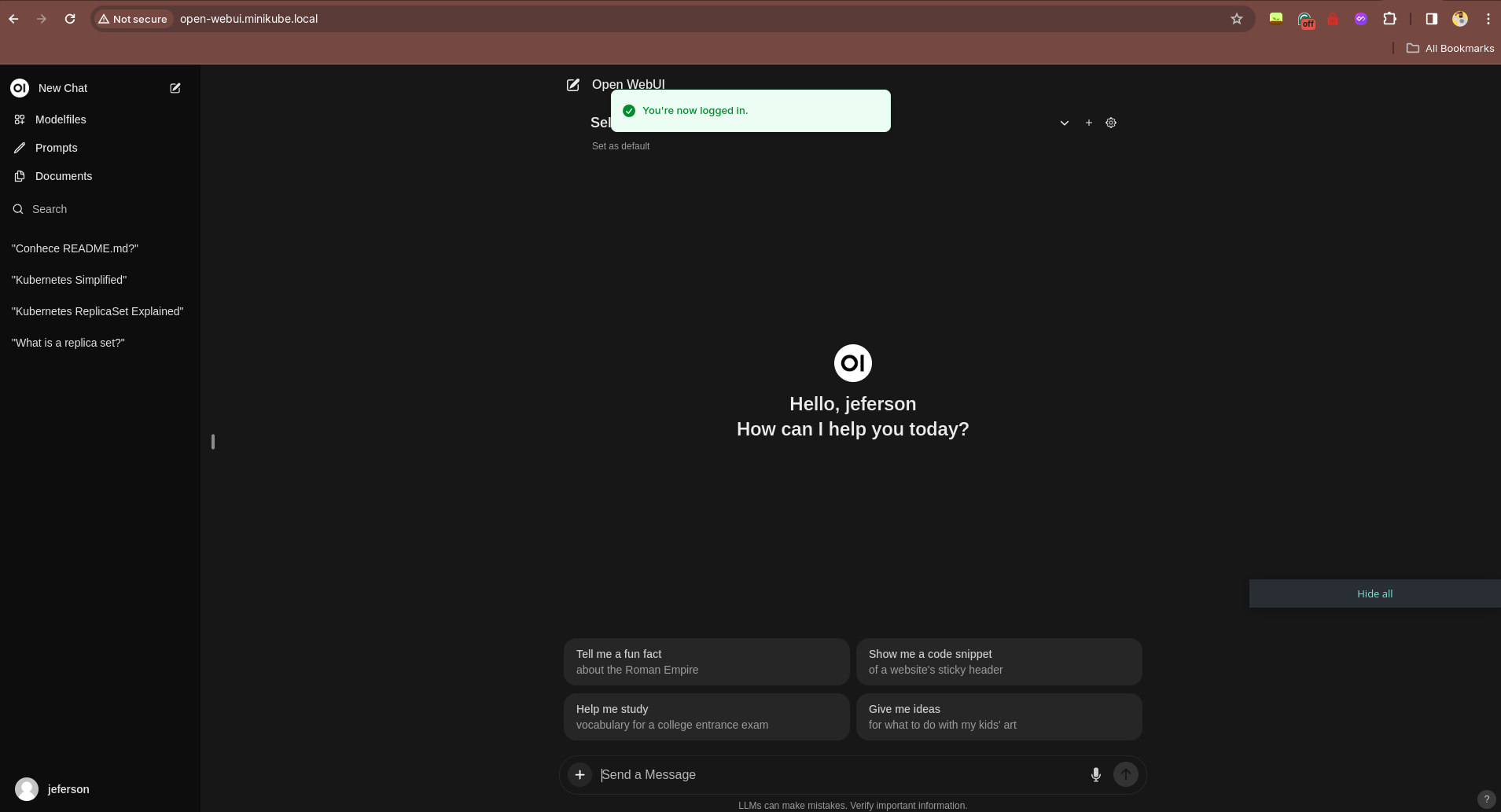
Na parte superior da tela, você pode ver o nome do modelo que você está utilizando, nós estamos utilizando o modelo Llama2, que definimos lá no arquivo values.yaml do Ollama. Se precisar de outros, você pode adicionar na lista de modelos no chart Helm do Ollama e depois fazer o helm upgrade para atualizar o Ollama no Kubernetes. É bem simples!
Acho que o nosso serviço está completo, por enquanto! Vamos ver o que podemos aprontar na parte 3 dessa série! 😄
Para acessar o Parte 1, clique aqui.
LINUXtips
Entre em contato
-
contato@linuxtips.io
-
empresas@linuxtips.io
-
Política de Cancelamento
-
Manual do Estudante
-
Termos de Uso